Linux利用grep配合正则表达式显示非空注释行内容
本文共 3106 字,大约阅读时间需要 10 分钟。
- 显示 /etc/inittab 文件中以 ‘#’ 号后跟着一个或多个空白字符开头并且之后是任意个非空白字符的行
- 查看/etc/inittab的内容
[04:16:42 rooter@C8-3-55 ~]#cat /etc/inittab# inittab is no longer used.## ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.## Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target## systemd uses 'targets' instead of runlevels. By default, there are two main targets:## multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5## To view current default target, run:# systemctl get-default## To set a default target, run:# systemctl set-default TARGET.target
- 显示#开头的注释行
[04:17:54 rooter@C8-3-55 ~]#cat /etc/inittab | grep ^## inittab is no longer used.## ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.## Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target## systemd uses 'targets' instead of runlevels. By default, there are two main targets:## multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5## To view current default target, run:# systemctl get-default## To set a default target, run:# systemctl set-default TARGET.target
- 敲错了啥都不显示 没有加-E不支持正则表达式
[04:19:33 rooter@C8-3-55 ~]#cat /etc/inittab | grep ^#[[:blank:]]+[04:20:28 rooter@C8-3-55 ~]#cat /etc/inittab | grep '^#[[:blank:]]+'
- 显示#开头,其后是一个或多个空格的行
[04:20:38 rooter@C8-3-55 ~]#cat /etc/inittab | grep -E '^#[[:blank:]]+'# inittab is no longer used.# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target# systemd uses 'targets' instead of runlevels. By default, there are two main targets:# multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5# To view current default target, run:# systemctl get-default# To set a default target, run:# systemctl set-default TARGET.target
- 显示#开头之后是1个或多个空格,之后是非空格的行
[04:21:06 rooter@C8-3-55 ~]#cat /etc/inittab | grep -E '^#[[:blank:]]+[^[:blank:]]+'# inittab is no longer used.# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target# systemd uses 'targets' instead of runlevels. By default, there are two main targets:# multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5# To view current default target, run:# systemctl get-default# To set a default target, run:# systemctl set-default TARGET.target
- 显示#开头,之后是一个或多个空格,然后是非空格及任意字符的行
[04:21:56 rooter@C8-3-55 ~]#cat /etc/inittab | grep -E '^#[[:blank:]]+[^[:blank:]]+.*'# inittab is no longer used.# ADDING CONFIGURATION HERE WILL HAVE NO EFFECT ON YOUR SYSTEM.# Ctrl-Alt-Delete is handled by /usr/lib/systemd/system/ctrl-alt-del.target# systemd uses 'targets' instead of runlevels. By default, there are two main targets:# multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5# To view current default target, run:# systemctl get-default# To set a default target, run:# systemctl set-default TARGET.target
问题:
- #号开头之后紧跟着1个以上空格的及任意字符的行,为啥把#后跟空行也过滤掉了?
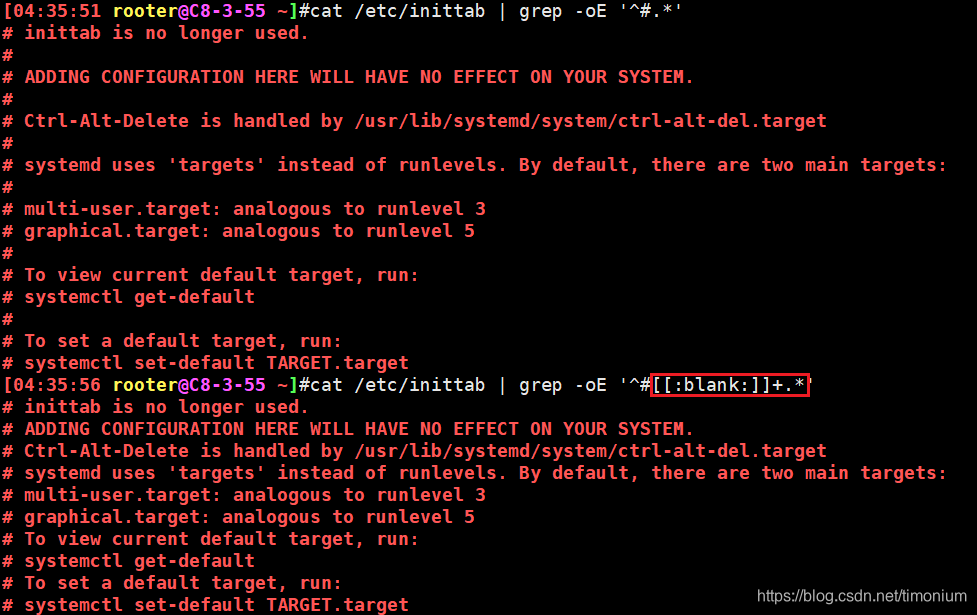
回答:
- 看起来像#空行,但人家直接#$就结束了!
- 所以用一个以上blank就把看起来像空行的过滤掉了
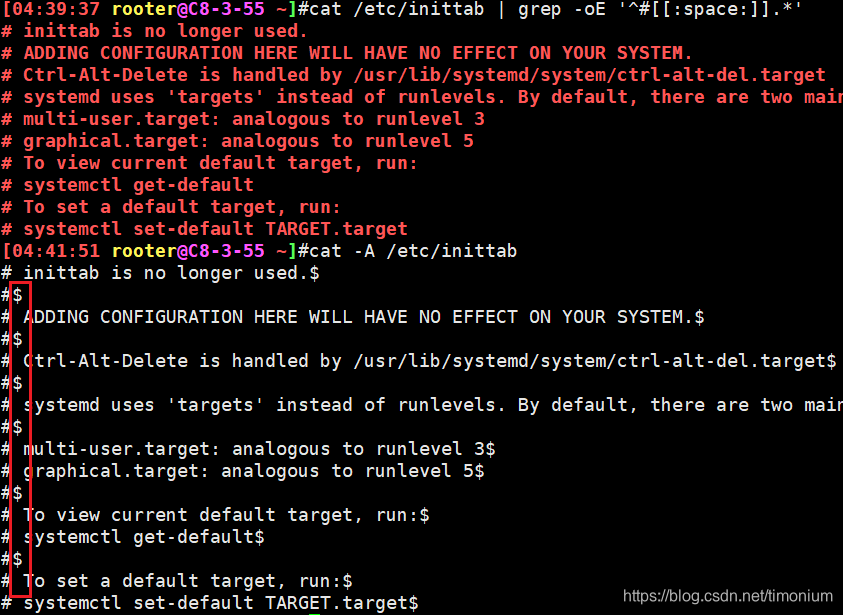
转载地址:http://eqkzz.baihongyu.com/
你可能感兴趣的文章
MySQL 面试题汇总
查看>>
MySQL 面试,必须掌握的 8 大核心点
查看>>
MySQL 高可用性之keepalived+mysql双主
查看>>
mysql 默认事务隔离级别下锁分析
查看>>
Mysql--逻辑架构
查看>>
MySql-2019-4-21-复习
查看>>
mysql-5.7.18安装
查看>>
MySQL-Buffer的应用
查看>>
mysql-cluster 安装篇(1)---简介
查看>>
mysql-connector-java各种版本下载地址
查看>>
mysql-EXPLAIN
查看>>
mysql-group_concat
查看>>
MySQL-redo日志
查看>>
MySQL-【1】配置
查看>>
MySQL-【4】基本操作
查看>>
Mysql-丢失更新
查看>>
Mysql-事务阻塞
查看>>
Mysql-存储引擎
查看>>
mysql-开启慢查询&所有操作记录日志
查看>>
MySQL-数据目录
查看>>